簡單來說,就是把網站上面的資料擷取下來,但通常需要用到電腦輔助之資料擷取不可能只有一筆,而是會有著大筆的資料,而這之間也有可能參雜了許多非文字資料,圖片、影片、影音等...。這時侯我們就需要 ** 網路爬蟲 ** 來幫我們完成,而每隻爬蟲的程式都做著不一樣的爬蟲機制。
而我們透過browser所看到的網頁呈現,跟爬蟲機制所看到的並不相同,他們看到的是 網頁原始碼。
而利用Python來撰寫爬蟲是因為它有幾個優點,具有可讀性與簡潔性,看一隻程式最好的莫過於直觀的理解程式語言想表達的。
今天先來簡介一個最簡單的例子,以 https://www.google.com.tw/ 網頁來做示範。
# import requests 套件包
import requests
# GET請求抓資料
page = requests.get('https://www.google.com.tw/')
#印出網頁程式碼
print(page.text)
結果如下
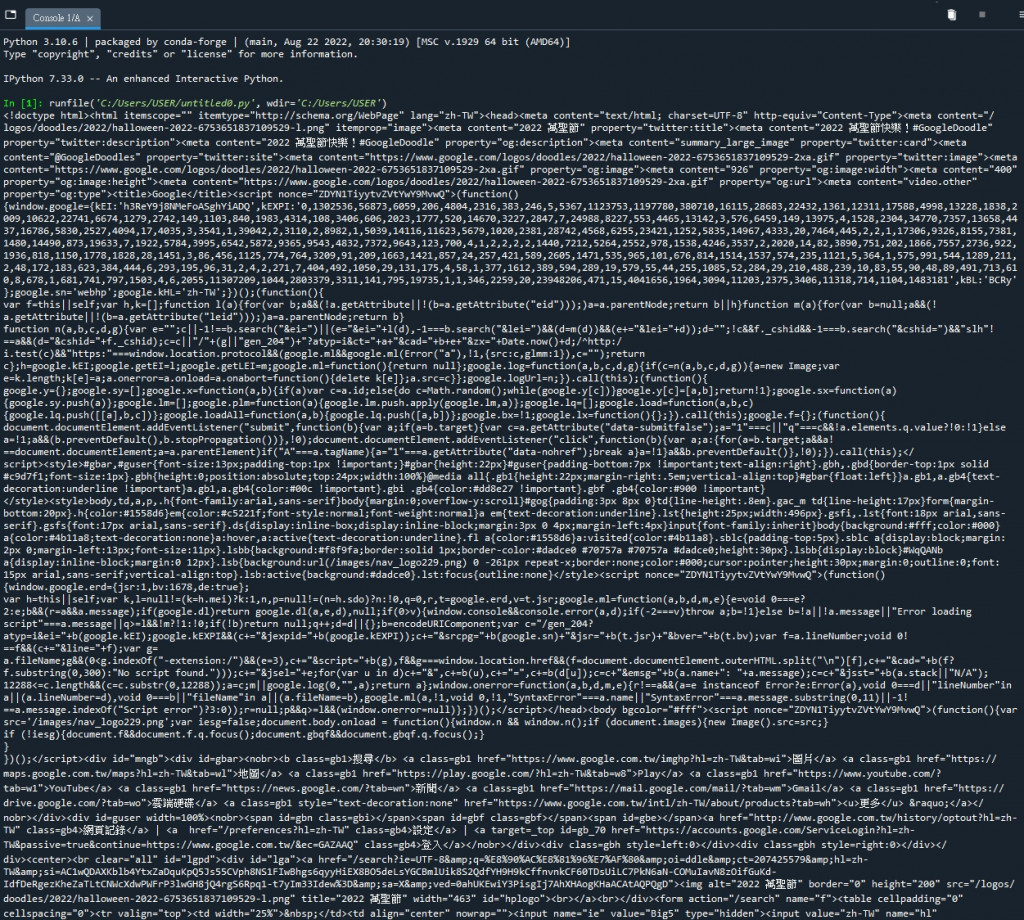


 iThome鐵人賽
iThome鐵人賽